
前言
云音乐前端性能监控平台,底层使用了 Lighthouse 进行审计评分,在实践过程中我们积累了一些 Lighthouse 内部实现的研究经验,希望通过这篇文章可以分享给各位读者。
本篇文章基于 Lighthouse 5.2.0 版本,介绍了 Lighthouse 的测试流程、架构模块实现、性能指标的计算等。通过这篇文章,读者可以了解到 Lighthouse 是如何做自动化测试的、如何在 Lighthouse 的框架上自定义一些审计项、关键的性能指标是如何模拟计算的。
本篇文章会按以下四个部分展开:
- Lighthouse 简介
- Lighthouse 测试流程
- Lighthouse 模块实现
- Lighthouse 性能指标计算
Lighthouse 简介
Lighthouse 是一个开源的自动化工具,用于改进网络应用的质量。只要为 Lighthouse 提供一个需要审查的网址,它将针对此页面运行一连串的测试,然后生成一个有关页面性能的报告。
Lighthouse 使用方式
目前官方提供了 4 种使用方式:
以 Chrome 开发者工具为例,在 Audits 面板下,用户可以配置测试平台、测试类目、限速方式等,可以方便快捷地发起一次测试。
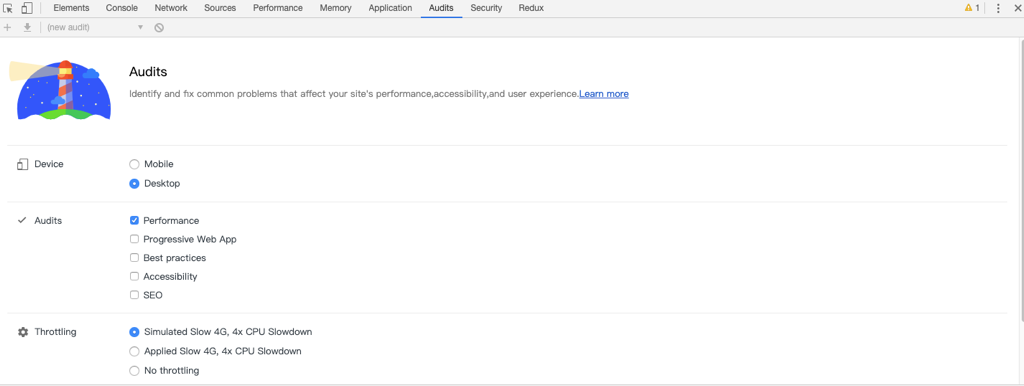
Lighthouse 测试报告
测试结束后,默认会生成 HTML 格式的报告,如下图所示,在报告中涵盖了 5 大类别(categories)的测试评分:

每个类别都包含一系列的审计项(audit),针对审计项的运行结果,Lighthouse 会给出特定的优化建议与诊断结果帮助开发者有针对性地进行优化。
本节简要介绍了 Lighthouse 的使用方式与测试报告组成,下一节将介绍 Lighthouse 的测试流程。
Lighthouse 测试流程
我们以 Node CLI 的方式进行测试,分析 Lighthouse 的测试流程。
参考官方文档,安装好 CLI 后,输入如下命令,可以进行一次测试
lighthouse --only-categories=performance https://google.com
注:以上命令只进行 performance 类别测试。
在 CLI 中会输出测试过程中的日志,截图显示如下,在日志中,可以看出测试大致分为如下几个阶段:
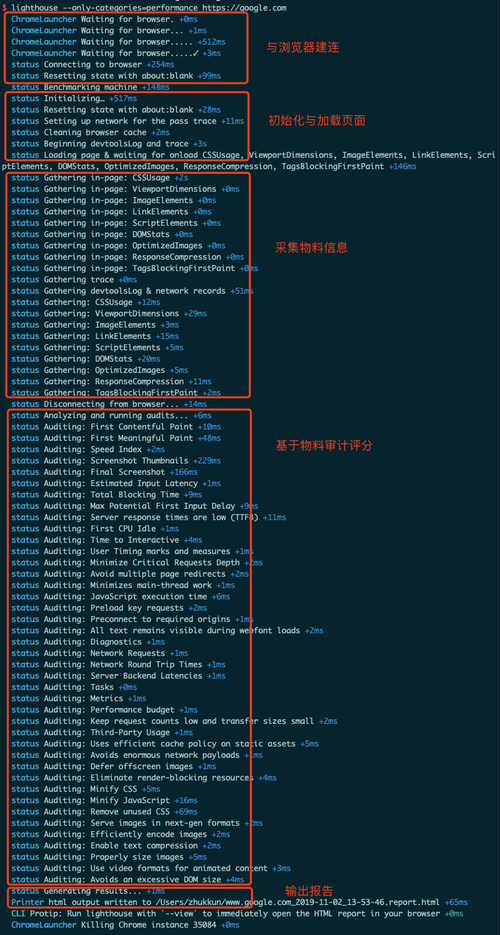
通过输出的日志,可以画出 Lighthouse 的测试流程图:
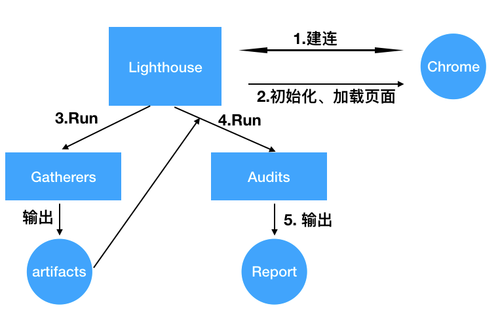
- Lighthouse 与浏览器建立连接。
- 测试的初始化配置与加载待测试页面。
- 在页面加载过程中,运行一系列的采集器(gatherers),每个采集器都会收集自己的目标信息,并生成中间产物(artifacts)。
- 运行一系列的审计项(audits),每个审计项都会从中间产物(artifacts)中获取所需的数据,计算出各自的评分。
- 基于审计项的评分计算出大类的评分,汇总生成报告。
本节基于 Lighthouse 的测试日志,介绍了 Lighthouse 的测试流程,下节将介绍流程中的模块实现。
Lighthouse 模块实现
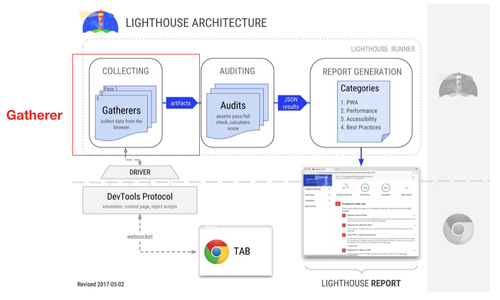
初步了解了基本的测试流程后,我们再看下官方给出的 Lighthouse 架构图:
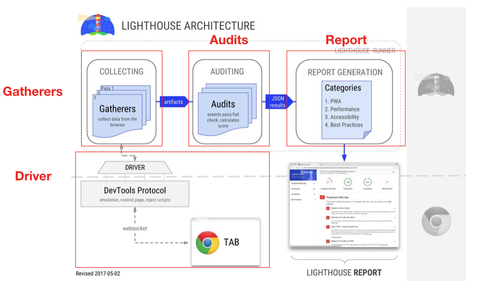
这张图中体现了测试的主要流程,从中也可以圈出 4 个主要模块,下文会对这几个模块做逐个讲解。
Driver 模块
双向通信与 DevTools 协议
Chrome 浏览器在启动的时候,可以通过 --remote-debugging-port 参数设置远程调试端口,如以下命令可以打开 Chrome 并设置远程调试端口为 9222。
chrome.exe --remote-debugging-port=9222
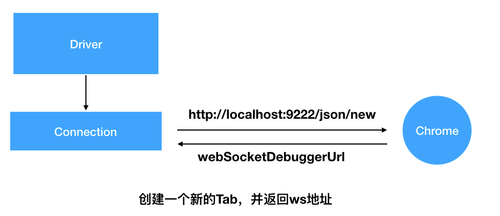
之后就可以使用地址 http://localhost:9222 进行远程调试了,比如以下命令可以让 Chrome 浏览器打开一个新的 Tab。
curl http://localhost:9222/json/new
该命令还会返回此 Tab 的相关信息,其中需要关注的是 webSocketDebuggerUrl,这是该 Tab 的 WebSocket 连接地址。
{
"id": "29989D...",
"url": "about:blank",
"webSocketDebuggerUrl": "ws://localhost:9222/devtools/page/29989D...",
...
}
Driver 模块持有 Connection 实例(负责与浏览器进行通信),该实例在初始化的时候,正是通过调用远程调试端口的/json/new指令打开一个新的 Tab,并使用返回的 webSocketDebuggerUrl 与浏览器建立 WebSocket 连接,之后就可以进行双向通信。
- 新开一个 Tab
- 建立 WebSocket 连接
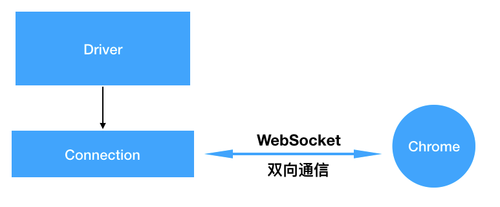
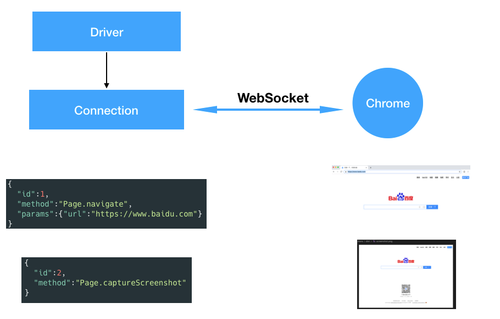
双方建立 WebSocket 连接后,必须使用一种数据格式协议进行通信,该协议就是 Chrome DevTools Protocol,此协议以 JSON 为格式,定义指令的方法名与参数。
如下图所示,发送 Page.navigate 指令可以让 Chrome 导航至目标页面。发送 Page.captureScreenshot 指令可以让 Chrome 生成当前页面的截图数据。
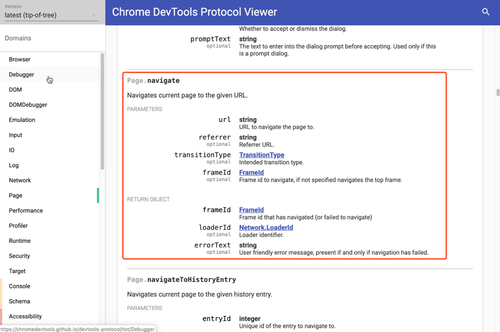
在该协议的文档中,所有的控制指令和事件被划分至多个领域(Domains)如 Page、Network 等。打开 Page 领域,可以找到示例指令 Page.navigate 的详细说明:
除了 navigate、captureScreenshot 等主动调用的指令外,当我们调用某个领域的 enable 指令后,后续就可以接收到该领域推送的通知事件。
Lighthouse 通过 Chrome DevTools Protocol 定义的主动指令与事件通知,就实现了操控 Chrome 浏览器,和感知页面加载过程中的各个事件。
日志记录
Driver 模块中的另外 2 个重要实例是 DevtoolsLog、NetworkRecorder,他们用于将浏览器发出的通知事件进行结构化的存储。其中 DevtoolsLog 会记录各个领域的全量日志,NetworkRecorder 只存储网络相关日志,并会分析出当前网络请求状态(繁忙、空闲)等。
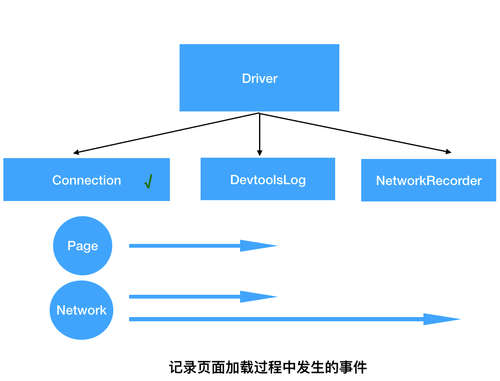
存储的日志信息将在后续的审计(Audits)模块中使用,下文会继续提到他们。
仿真器(emulation)
Driver 模块中最后值得一提的部分是仿真器(emulation),该模块的作用是模拟测试设备,如模拟 移动端 / PC 端、屏幕的尺寸,模拟设备的 UserAgent、Cookie、网络限速等。
这些模拟功能的设置,也是通过 Connection 模块向 Chrome 浏览器发送对应领域的操控指令实现的。
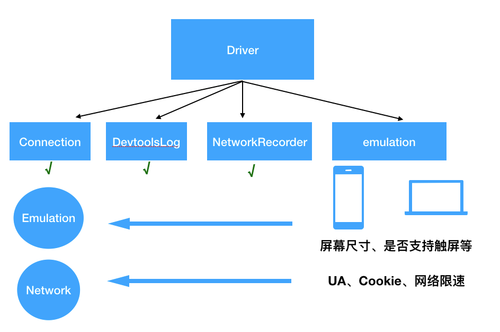
至此我们分析完了 Driver 模块的主要组成部分,我们来简单总结下:负责与浏览器的双向通信、记录事件日志、模拟器的设置等。
Gatherer 模块
该模块的一个重要概念是 pass,官方是这样定义 pass 的:
controls how to load the requested URL and what information to gather about the page while loading.
即控制页面如何加载,并决定在页面加载过程中采集哪些信息
defines basic settings such as how long to wait for the page to load and whether to record a trace file. Additionally a list of gatherers to use is defined per pass. Gatherers can read information from the page to generate artifacts which are later used by audits to provide you with a Lighthouse report.
即定义页面加载等待时间、是否记录 trace 文件等配置。每个 pass 还定义了一个 gatherers 列表,gatherers 可以从页面中读取需要的信息并生成一个中间产物, 中间产物将会用于后续的审计分析,并最终生成测试报告。
了解了 pass 的定义,来看一个具体的 pass 配置:
{
passes: [{
passName: 'defaultPass',
recordTrace: true, // 是否记录Trace信息
useThrottling: true, // 是否使用限速
gatherers: [ // gatherers列表
'css-usage',
'viewport-dimensions',
'runtime-exceptions',
'console-messages',
'anchor-elements',
'image-elements',
'link-elements',
'meta-elements',
'script-elements',
'iframe-elements',
... // 省略
],
},
... // 省略
}
其中的 gatherers 是我们需要关注的重点,每一个 gatherer,在代码仓库中都有与之对应的同名实现文件,并且都继承自相同的父类 Gatherer,其中定义了三个模板方法,子类只需实现关心的模板方法即可。
class Gatherer {
// 在页面导航前
beforePass(passContext) {}
// 在页面loaded后
pass(passContext) {}
// 在页面加载完毕,且trace信息收集完毕后
afterPass(passContext, loadData) {}
}
以一个比较简单的 Gatherer 具体实现 RuntimeExceptions 为例,该实例实现了 beforePass 、afterPass 两个生命周期模板方法,其中 driver.on 正是通过上文介绍的 Driver 模块实现的事件监听。
const Gatherer = require("./gatherer.js");
class RuntimeExceptions extends Gatherer {
constructor() {
super();
this._exceptions = [];
this._onRuntimeExceptionThrown = this.onRuntimeExceptionThrown.bind(this);
}
onRuntimeExceptionThrown(entry) {
this._exceptions.push(entry);
}
// 在页面导航前,注册事件监听器,采集错误信息
beforePass(passContext) {
const driver = passContext.driver;
driver.on("Runtime.exceptionThrown", this._onRuntimeExceptionThrown);
}
// 在页面加载完毕后,解除事件监听
async afterPass(passContext) {
await passContext.driver.off(
"Runtime.exceptionThrown",
this._onRuntimeExceptionThrown
);
return this._exceptions;
}
}
有了这个参考示例,我们也可以轻松地写一个自定义的 Gatherer,比如用于采集页面标题的 gatherer:
const Gatherer = require("./gatherer.js");
function getPageTitle() {
return document.title;
}
class PageTitle extends Gatherer {
afterPass(passContext) {
return passContext.driver.evaluateAsync(`(${getPageTitle.toString()}())`);
}
}
我们只重写了 afterPass 方法,在该生命中期中,将脚本通过 driver 模块发送给浏览器执行,并获取到执行结果。
当 pass 中定义的所有 gatherers 运行完后,就会生成一个中间产物 artifacts,此后 Lighthouse 就可以断开与浏览器的连接,只使用 artifacts 进行后续的分析。
总结下 Gatherer 模块,该模块会通过 pass 这个配置,定义页面如何加载,并运行配置的所有 gatherers 来采集页面加载过程中的信息,并生成中间产物 artifacts。有了 artifacts,就可以进入下一步的 Audits 模块。
Audits 模块
与 gatherers 类似,在配置文件中也会定义需要运行的 audits,每一个 audits 也都有与之对应的同名实现文件。
{
audits: [
'errors-in-console',
'metrics/first-contentful-paint',
'metrics/first-meaningful-paint',
'metrics/speed-index',
'metrics/first-cpu-idle',
'metrics/interactive',
'screenshot-thumbnails',
'final-screenshot',
// 省略
],
// 省略
}
我们还是从最为简单的 errors-in-console 入手,了解下一个 audit 是如何实现的。
在每个 audit 中都会定义一个静态方法meta(),对该 audit 进行描述,并声明所需的 artifacts,ErrorLogs 这项 audit 就声明了其需要上文提到的 RuntimeExceptions 所生成的中间产物。
class ErrorLogs extends Audit {
static get meta() {
return {
id: "errors-in-console",
title: str_(UIStrings.title),
failureTitle: str_(UIStrings.failureTitle),
description: str_(UIStrings.description),
requiredArtifacts: ["ConsoleMessages", "RuntimeExceptions"],
};
}
}
Audit 实例需要实现的另一个模板方法是audit(),在该方法中可以拿到所需的中间产物,并基于中间产物计算出本项 audit 的得分与详情。
static audit(artifacts) {
// 获取所需的中间产物
const runtimeExceptions = artifacts.RuntimeExceptions;
// 数据的过滤与转换
const runtimeExRows =
runtimeExceptions.filter(entry => entry.exceptionDetails !== undefined)
.map(entry => {
const description = entry.exceptionDetails.exception ?
entry.exceptionDetails.exception.description : entry.exceptionDetails.text;
return {
source: 'Runtime.exception',
description,
url: entry.exceptionDetails.url,
};
});
// 省略表格详情生成代码
...
// 计算出审计项的得分
const numErrors = tableRows.length;
return {
score: Number(numErrors === 0),
numericValue: numErrors,
details,
};
}
有了上面的示例,我们就可以参照实现一个自定义审计项,如审计页面标题:
class PageTitle extends Audit {
static get meta() {
return {
id: "page-title",
title: "title of page document",
failureTitle: "Does not have page title",
description: "This audit get document.title when page loaded",
requiredArtifacts: ["PageTitle"],
};
}
static audit(artifacts) {
return {
score: artifacts.PageTitle ? 1 : 0,
displayValue: artifacts.PageTitle || "none",
};
}
}
当运行完配置文件中定义的所有审计项后,就得到了每个审计项的评分与详情,后续就进入 Report 模块。
Report 模块
在配置文件中,会定义每个测试类别所需的审计项,以及每个审计项所占的权重。如下所示的为性能(performance)这项测试类别所需的审计项:
{
'performance': {
title: str_(UIStrings.performanceCategoryTitle),
auditRefs: [
{id: 'first-contentful-paint', weight: 3, group: 'metrics'},
{id: 'first-meaningful-paint', weight: 1, group: 'metrics'},
{id: 'speed-index', weight: 4, group: 'metrics'},
{id: 'interactive', weight: 5, group: 'metrics'},
{id: 'first-cpu-idle', weight: 2, group: 'metrics'},
{id: 'max-potential-fid', weight: 0, group: 'metrics'},
// 省略
]
},
}
在最终汇总阶段,Lighthouse 会基于该配置文件以及上一个环节中计算出的每个审计项的评分,加权计算出 performance 的评分。并基于每个审计项的评分与种类,将审计项划分为通过与不通过,对于不通过的审计项会给出详细的测试详情与优化指引。
FCP 等性能指标审计项的实现
在上文介绍整体测试流程的过程中,我选择了最为简单的审计项展开介绍,本节会挑选大家更为关心的性能审计指标如 FCP 展开介绍。
FCP(First Contentful Paint) 首次内容绘制时间,是从页面导航开始,到浏览器从 DOM 中渲染出首个内容的时间。
限速模拟
由于页面性能受宿主机网络与 CPU 频率等参数的影响较大,Lighthouse 提供了三种方式供模拟较差的宿主机环境,其背后的逻辑是,如果页面能够在较差的环境下达到一个较好的测试分数、那么大部分用户对页面的直观感受都会较好。
在 Chrome Devtools 的 Audits 面板中,可以看到三种限速方式:

上图配置项分别对应下面三种限速方式的介绍
simulated
Throttling is simulated, resulting in faster audit runs with similar measurement accuracy
即限速是模拟的(加载页面时不进行限速,加载完页面后,模拟计算出在限速条件下的性能指标值),所以可以在较快的速度下地完成审计并有相似的测试精度。
devtools
Typical DevTools throttling, with actual traffic shaping and CPU slowdown applied
即通过 DevTools 进行限速,页面是在一个真实受限的网络与降速 CPU 条件下加载的。
no throttling
No network or CPU throttling used. (Useful when not evaluating performance)
即 Lighthouse 不进行额外的限速,通常在不进行性能测试、或开发者自行对宿主机进行限速时使用该项。
在三种限速方式中,Lighthouse 真正对网络与 CPU 进行限速的只有 devtools 这种限速方式,实现的方式是通过上文提到的 Driver 模块发送对应领域的指令给 Chrome 浏览器:
// 开启CPU限速
function enableCPUThrottling(driver, throttlingSettings) {
const rate = throttlingSettings.cpuSlowdownMultiplier;
return driver.sendCommand("Emulation.setCPUThrottlingRate", { rate });
}
// 开启网络限速
function enableNetworkThrottling(driver, throttlingSettings) {
// 省略部分代码
return driver.sendCommand("Network.emulateNetworkConditions", conditions);
}
Trace 信息
在上文介绍 pass 时,我们提到其中有一个参数用来控制是否收集 Trace 信息,Trace 信息是什么?它又有什么用呢?
其实我们大部分同学都已经接触过 Trace 信息,它的可视化展示就在 Chrome devtools 中 Performance 面板:
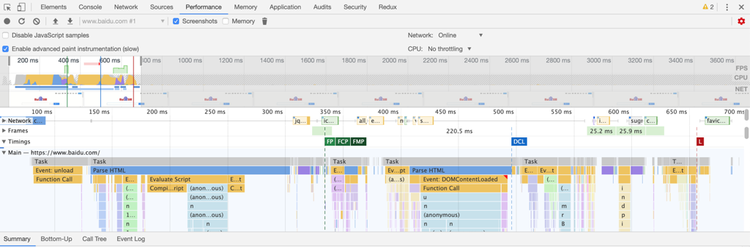
在这个可视化面板中,可以看到页面加载过程中关键渲染节点 FP、FCP、FMP 等,并可以看到主线程进行的 Parse HTML、Layout、JS 的执行依赖情况等。
当 pass 中配置了开启收集 Trace 信息时,Lighthouse 在页面加载完毕后,就可以拿到完整的 Trace 信息, 从中可以知道页面加载时的 FCP、FMP 等关键渲染节点。
FCP 的模拟计算
当使用 devtools、no throttling 这两种方式进行限速时,由于页面就是在真实受限的网络条件下加载的,Trace 信息中给出的 FCP 值就是限速条件下的 FCP 值,所以 Lighthouse 无需进行任何额外的加工处理。
但在 simulated 这种限速方式下,页面是在没有限速的条件下加载,所以 Trace 中的 FCP 是不限速时的 FCP,Lighthouse 需要通过模拟计算的方式,得出在给定限速条件下的 FCP 估算值。接下来我们重点介绍 simulated 这种模拟方式下,FCP 的计算。
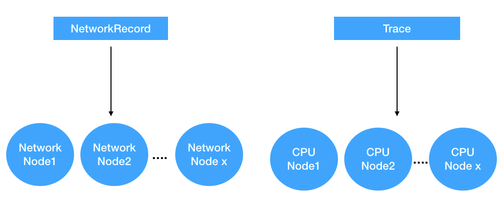
上文我们提到在 Driver 模块中有个 NetworkRecorder,这个模块会记录页面加载过程中的所有网络请求详情,Lighthouse 会为每个有效的网络请求事件建立一个对应的 Network Node 节点。
Trace 信息中也会记录页面加载过程中 CPU 执行事件,Lighthouse 会为每个有效的 CPU 事件建立一个对应的 CPU Node 节点。
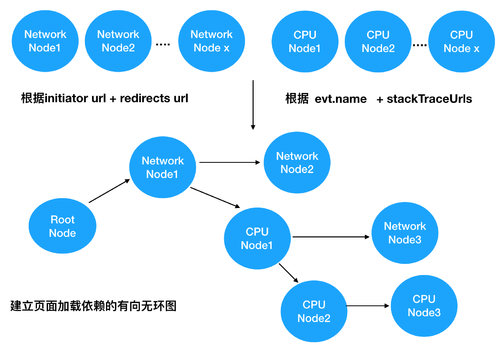
紧接着,Lighthouse 会从 Network 请求节点中找出根节点(请求 Document 的节点),并根据节点依赖算法,建立起 CPU 节点与 Network 节点之间的依赖,最终生成页面加载依赖的有向无环图:
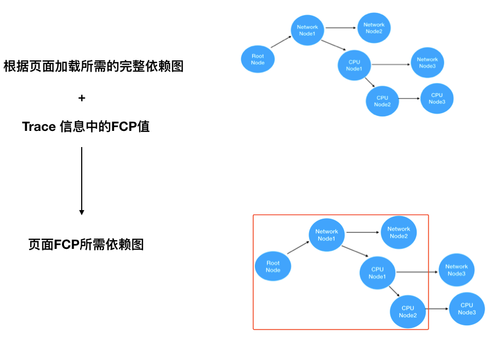
建立了页面加载所需的完整依赖图后,Lighthouse 会结合 Trace 信息中的 FCP 事件时间,分析出页面 FCP 所需的的依赖图:
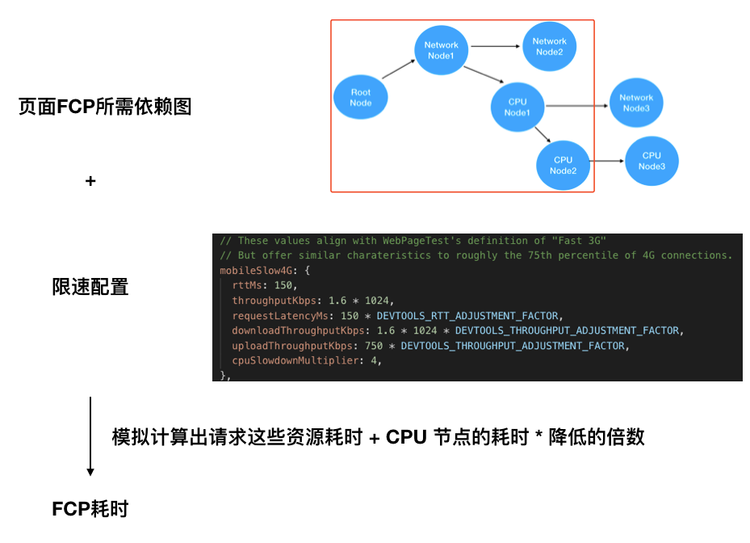
有了页面 FCP 所需的依赖图后,Lighthouse 模拟计算出,在限速条件下,请求依赖图中的资源,执行依赖图中的 CPU 事件,所需的耗时,以此得出在特定限速条件下的 FCP 估算值。
模拟 HTTP 请求
Lighthouse 通过模拟 HTTP 的方式,计算出在特定网络条件下的资源下载耗时,而不是真实地发起网络请求,我们来看下 Lighthouse 是如何做模拟的。
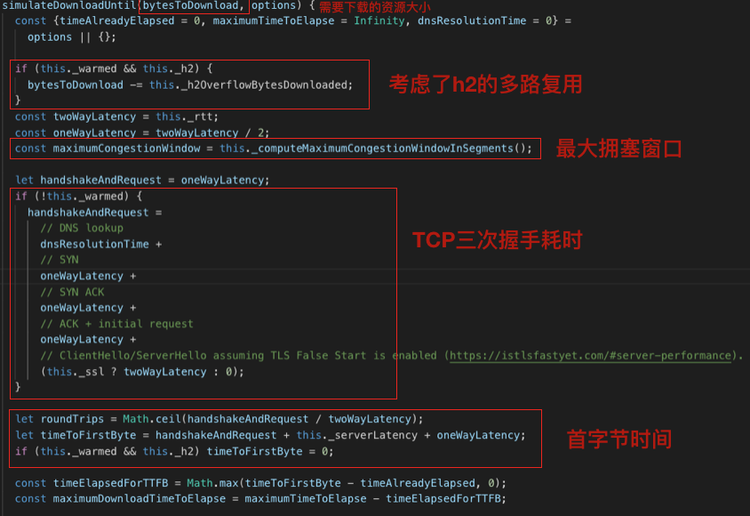
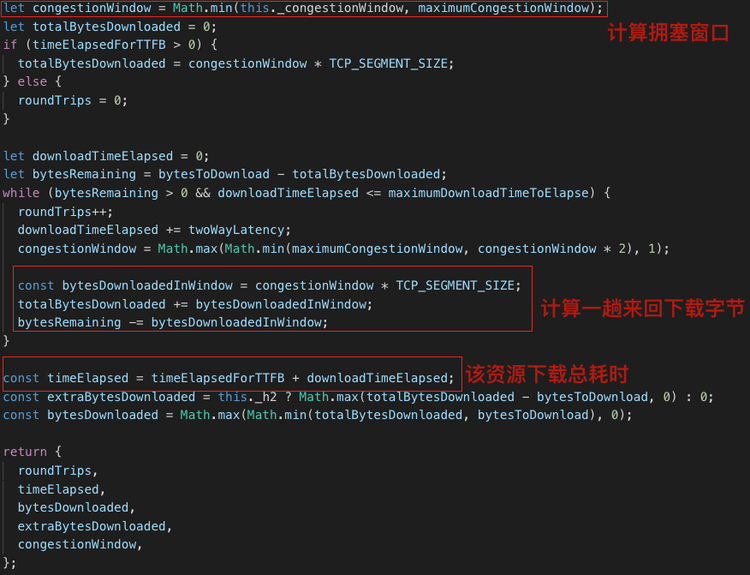
在上述的代码中,我们看到 Lighthouse 完全是通过模拟 HTTP 的方式,计算出了一个资源在特定网络条件下,所需要的耗时。并且这个模拟考虑了 HTTP2 多路复用技术、 请求是否 KeepAlive、TCP 三次握手、拥塞窗口等细节。
我们用一张图来总结和对比一下,两种限速方式计算 FCP 的流程差异:
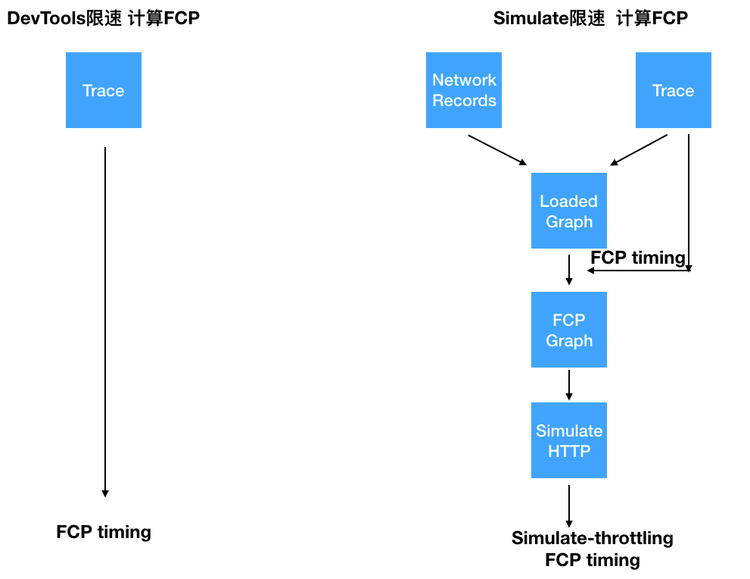
可以看出两种限速方式,都是以 DevTools 给出的 Trace 信息为基础,在 Simulate 限速方式下,在拿到 FCP 值后,还需要模拟计算在限速条件下的估算值。在 Simulate 限速方式下,其他性能指标如 FMP、SpeedIndex 等也是通过类似的方式进行模拟计算,至此我们分析完了 Lighthouse 性能指标 FCP 审计项的实现原理。
总结
本篇文章为大家简要介绍了 Lighthouse、并分析了 Lighthouse 的测试流程与主要的模块实现,最后向大家介绍了关键性能指标 FCP 的模拟计算方式,希望能对大家有所收获。文末会贴出文章中提到的模块的源码导航,有兴趣的朋友可以看下,欢迎大家进行交流。
源码导航
Driver 模块
Gatherer 模块
Audit 模块
FCP 计算
- audit/fcp
- computed/fcp
- computed/lantern-fcp
- computed/lantern-metric
- computed/page-dependency-graph
- dependency-graph/base-node
- dependency-graph/tcp-connection